※ 이번 포스팅 실습은 Windows Platform으로 진행됩니다. ※
다양한 카테고리의 웹 사이트 중,
어떠한 특정 사이트 링크들을 모아놓은 사이트 이를테면, 각종 전자기기들의 가격, 가성비, 스펙 등 비교하는 사이트들 많다.
어떻게 한걸까?
바로 웹페이지를 스크랩핑하여 페이지에 노출시킨것이다.
스크래핑이란,
웹 페이지 또는 시스템에 있는 데이터 중에서 필요한 정보를 추출 및 가공하여 제공하는 것이다.
그렇게 데이터를 모으고 모으고 모으다보면 어마어마한 양의 데이터를 어딘가에 적재할 수 있게 된다.
그런 데이터를 빅 데이터(Big Data)라고 하는데,
빅 데이터는 다양한 의미가 있지만 기본적으로
하루 100GB초과하는 대부분의 데이터 스크림이 빅 데이터 범주에 속한다고 한다.
필자는 총 40TB정도의 데이터양의 경우 빅데이터라고 알고 있었다.
이렇게 계속 데이터를 소개하고 얘기하는 이유는 데이터는 이렇게 스크래핑하여 모으는 것이 가능하기 때문이다.
그리고 스크래핑을 자동화하여 만든 기술을 웹 크롤링(Web Crawling)이라고 한다.
정리하자면,
웹 스크래핑은 데이터를 추출 및 가공하는 기술
웹 크롤링은 웹 스크래핑을 자동화하여 프로그램화 하는 기술이다.
너무 글만 있는 것 같아 넣어봤다.
너무 복잡한 이야기는 집어 치우고 설명하면서 실습할 예정이다.
우선, 웹 스크래핑하는 방법은 다양하다.
파이썬, 자바스크립트 등(아는게 이거 밖에 없)이 있지만 가장 배우기 쉬운 파이썬으로 스크래핑 하겠다.
우선 아무 사이트나 해도 되지만 필자의 블로그 정보를 추출해보도록 하겠다.
추출할 정보는
글 제목, 내용, 카테고리, 블로그 주소, 블로그명, 블로거 닉네임
CMD를 실행한다.

보통 프로젝트를 시작하면, 프로젝트를 보관하기 위한 폴더를 생성한다.
프로젝트 폴더를 원하는 경로에 생성한다.
되도록이면 영어만 있는 경로에 둔다.
$> mkdir workspace; mkdir tistory-crawler
이제 여기에 스크래핑에 필요한 파이썬 라이브러리들을 설치할 것이다.
$> pip install bs4 requests
Collecting bs4
Using cached bs4-0.0.1.tar.gz (1.1 kB)
Collecting requests
Downloading requests-2.25.1-py2.py3-none-any.whl (61 kB)
|████████████████████████████████| 61 kB 1.3 MB/s
Collecting beautifulsoup4
Using cached beautifulsoup4-4.9.3-py3-none-any.whl (115 kB)
Collecting idna<3,>=2.5
Using cached idna-2.10-py2.py3-none-any.whl (58 kB)
Collecting urllib3<1.27,>=1.21.1
Downloading urllib3-1.26.4-py2.py3-none-any.whl (153 kB)
|████████████████████████████████| 153 kB 3.3 MB/s
Collecting chardet<5,>=3.0.2
Downloading chardet-4.0.0-py2.py3-none-any.whl (178 kB)
|████████████████████████████████| 178 kB 6.8 MB/s
Collecting certifi>=2017.4.17
Downloading certifi-2020.12.5-py2.py3-none-any.whl (147 kB)
|████████████████████████████████| 147 kB 6.8 MB/s
Collecting soupsieve>1.2
Downloading soupsieve-2.2.1-py3-none-any.whl (33 kB)
Using legacy 'setup.py install' for bs4, since package 'wheel' is not installed.
Installing collected packages: soupsieve, urllib3, idna, chardet, certifi, beautifulsoup4, requests, bs4
Running setup.py install for bs4 ... done
Successfully installed beautifulsoup4-4.9.3 bs4-0.0.1 certifi-2020.12.5 chardet-4.0.0 idna-2.10 requests-2.25.1 soupsieve-2.2.1 urllib3-1.26.4
라고 뜨는데, 중간에 Using legacy 'setup.py install' for bs4, since package 'wheel' is not installed. 이라고 뜨는 걸 보니 wheel이 설치가 안된 모양이다. 설치해준다.
설치가 다 됐으면 확인한다.
$> pip list
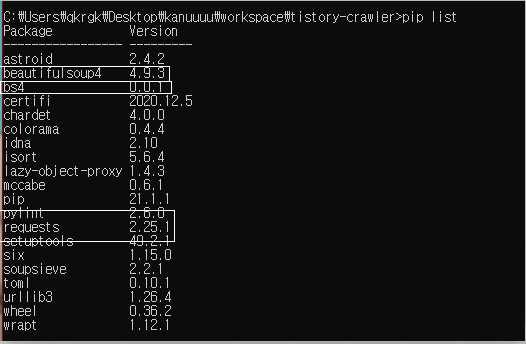
준비는 끝났다.
파이썬 파일을 만들고 내용을 채워준다.
먼저 필요한 라이브러리를 불러온다.
# crawler.py
import requests as req
from bs4 import BeautifulSoup as bs
requests는 HTTP 라이브러리다.
bs4는 웹페이지 데이터를 추출하는데 편리한 라이브러리다.
라이브러리를 불러온 후 뒤에 as를 붙이면 또다른 네임으로 대체 가능하니 참고하자.
그럼 이제 불러올 페이지를 requests로 불러온다.
...
url = 'https://developak.tistory.com/'
res = req.get(url)
print(res.status_code)불러온 페이지의 상태를 먼저 확인하기 위해 실행한다.
실행 결과는 200이 나올 것이다.(200이 아니면 시작도 못해요)
참고로 파이썬 파일을 실행하기 위해선
python .\crawler.py를 CMD에 입력하고 실행시킨다.
상태를 확인했으니 이제 웹 페이지 내용을 불러온다.
if res.status_code == 200:
soup = bs(res.content, 'lxml')
print(soup)다양한 방법으로 불러올수 있지만 해당방법이 가장 잘 불러오는 것 같아 이 방식을 채택했다.
코드를 설명하자면,
res.content는 req.get으로 요청한 주소의 페이지를 받아 내용을 가져오는 것이다.
그것을 lxml라이브러리로 특정 태그를 쉽게 가져올 수 있게 한다.
lxml도 python 라이브러리이기 때문에 pip로 설치한다.
lxml이란, 페이지를 css 선택자로 가져오기 위한 라이브러리이다.
다음은 bs다. requests로는 파이썬이 이해하는 객체구조로 만들어주지 못하기 때문에, 원하는 정보를 추출하기 어렵다.
그렇기 때문에 bs로 내용을 변환 및 가공하여 정보를 추출하는 것이다.
그 페이지의 전체 소스를 불러오기 때문에 해당 결과는 각자 확인하도록 한다.
다음은 내용을 가져와보도록 한다.
우선 글 제목부터 불러오도록 해보자. 보다 정확하게 가져오기 위해 가져올 페이지에서 F12를 눌러 개발자 도구를 연다.
(또는 Ctrl + Shift + i를 조합하면 된다.)
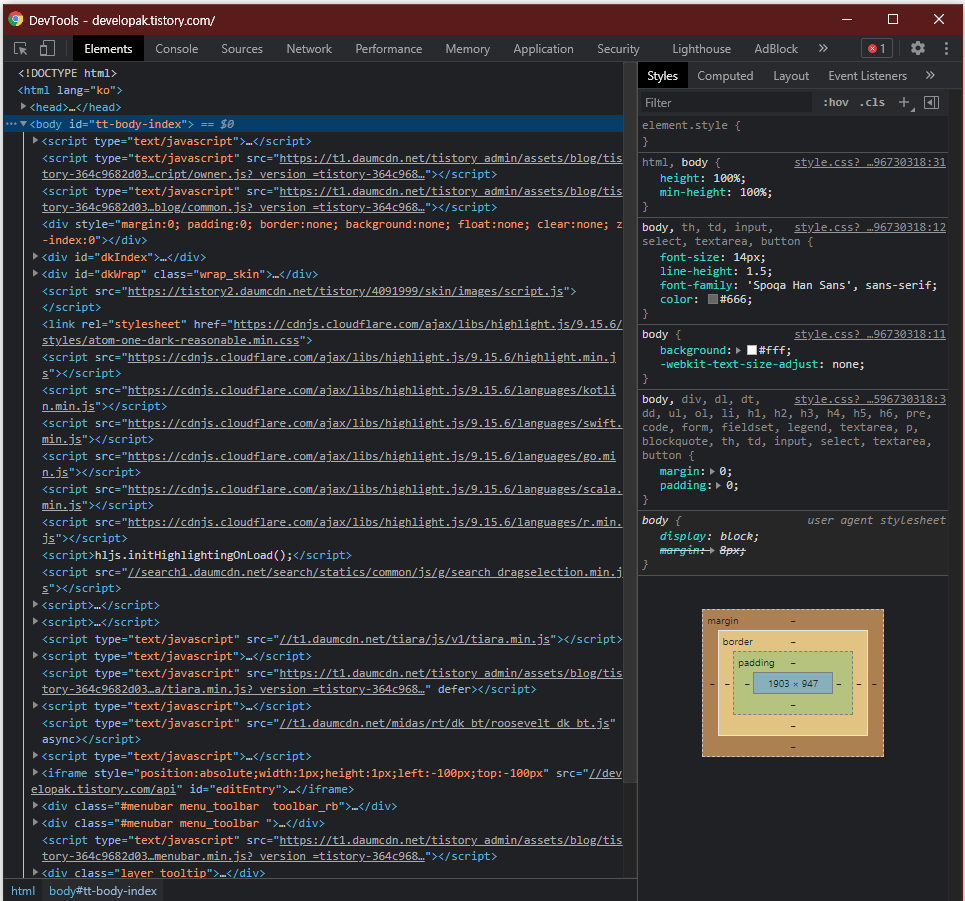
여기서 Ctrl + Shift + C를 조합하여 제목을 눌러주면
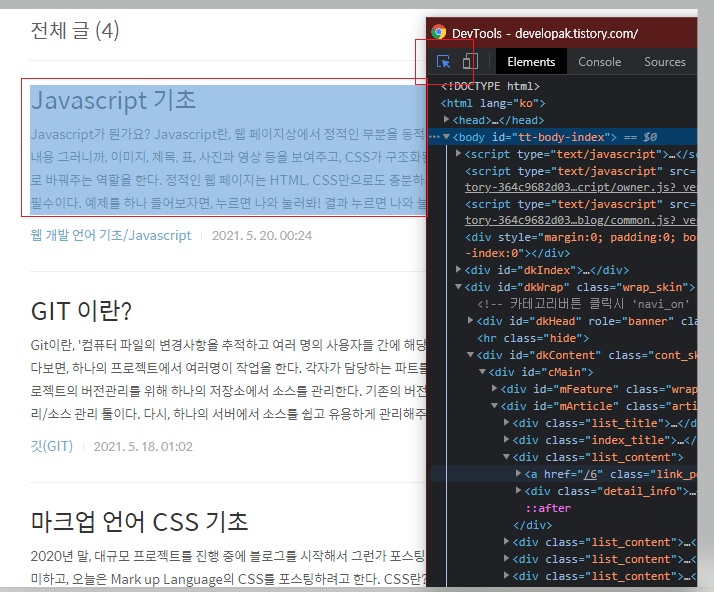
이런 형태가 된다. 누르면 해당 요소로 이동한다.

이 부분을 가져오는 방법은 두 가지가 있다.
하나는 select를 이용한다.
select는 css 문법을 사용하여 배열 형태로 가져올 수 있다.
그래서 필자는 이걸 많이 사용한다.
두번째는 find다.
find는 css 문법이 아닌 객체 형태로 가져온다
가져올 태그네임을 첫번째인자로 입력하고 선택자를 객체로 입력한다.
print(soup.select('.tit_post'))
print(soup.find('strong', { 'class': 'tit_post' }))두 객체를 작성한 부분이다.
select는 해당 부분을 전부 배열에 담아 반환하지만,
find는 한개만 반환한다. 모든 부분을 반환하기 위해선 findAll를 사용하면 된다.
그럼 일단 제목을 가져와 보도록 하겠다.
soup = bs(res.content, 'lxml')
tit_post_list = soup.select('.tit_post')
for tit_post in tit_post_list:
print(tit_post.text)실행하면,
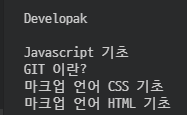
결과가 이렇게 나올 것이다.
이런식으로 나머지들도 전부 추출해준다.
# 글 내용
txt_post_list = soup.select('.txt_post')
for txt_post in txt_post_list:
print(txt_post.text)
# 글 카테고리
category_list = soup.select('.link_cate')
for category in category_list:
print(category.text)
# 블로그 주소
url = soup.select('link')[0].get('href')
print(url)
# 블로그명
blog_name = soup.select('.area_profile .tit_post')[0].text
print(blog_name)
# 블로거 닉네임
bloger_name = soup.select('.area_profile .txt_profile')[0].text
print(bloger_name)
그러나 이렇게 하나씩하면 어느 포스트의 제목에 내용인지 맞추기가 힘들다.
정보를 가공하여 소스를 재구성 해준다.
data_dict = {
'title': '',
'simple_content': '',
'category': '',
'url': '',
'blog_name': '',
'bloger_name': '',
}
data_list = []
list_content = soup.select('div.list_content')
# 블로그 주소
data_dict['url'] = soup.select('link')[0].get('href')
# 블로그명
data_dict['blog_name'] = soup.select('.area_profile .tit_post')[0].text
# 블로거 닉네임
data_dict['bloger_name'] = soup.select('.area_profile .txt_profile')[0].text
for content in list_content:
# 글 제목
data_dict['title'] = content.select('strong.tit_post')[0].text
# 글 내용
data_dict['simple_content'] = content.select('p.txt_post')[0].text
# 카테고리
data_dict['category'] = content.select('.link_cate')[0].text
data_list.append(data_dict)
먼저 가져올 데이터를 딕셔너리 형태로 정의해준다음,
추출할 데이터가 담긴 div를 리스트로 가져온다.
그 후 제목, 내용, 카테고리를 추출하고,
마지막에 주소, 블로그명, 블로거 닉네임을 가져온다.
잘 가져와졌는지 확인해보자.
for data in data_list:
for index, key in enumerate(data):
print('{0}: {1}'.format(key, data[key]))
print('\n----------------------------------------------------------------\n')
전체 소스
# _*_ coding:utf8 _*_
import requests as req
from bs4 import BeautifulSoup as bs
url = 'https://developak.tistory.com/'
res = req.get(url)
if res.status_code == 200:
soup = bs(res.content, 'lxml')
data_dict = {
'title': '',
'simple_content': '',
'category': '',
'url': '',
'blog_name': '',
'bloger_name': '',
}
data_list = []
list_content = soup.select('div.list_content')
for content in list_content:
# 글 제목
data_dict['title'] = content.select('strong.tit_post')[0].text
# 글 내용
data_dict['simple_content'] = content.select('p.txt_post')[0].text
# 카테고리
data_dict['category'] = content.select('.link_cate')[0].text
# 블로그 주소
data_dict['url'] = soup.select('link')[0].get('href')
# 블로그명
data_dict['blog_name'] = soup.select('.area_profile .tit_post')[0].text
# 블로거 닉네임
data_dict['bloger_name'] = soup.select('.area_profile .txt_profile')[0].text
data_list.append(data_dict)
for data in data_list:
for index, key in enumerate(data):
print('{0}: {1}'.format(key, data[key]))
print('\n----------------------------------------------------------------\n')